前言
这篇文章大部分内容为《Flask Web开发实战》第10章的删减章节,另外摘取了部分书中现有的内容。我为这篇文章单独编写了示例程序,GitHub地址为https://github.com/helloflask/github-login。运行示例程序的步骤如下:
$ git clone https://github.com/helloflask/github-flask.git
$ cd github-login
$ pipenv install --skip-lock # 如果没有安装pipenv,那么执行pip install pipenv
$ flask run # 在此之前需要在GitHub注册OAuth程序并将客户端ID与密钥写入程序,具体见下文
如果你想直接体验程序,可以访问部署在PythonAnywhere(“到处都是蛇”)的在线实例。
附注 第三方登录的原理是与第三方服务进行OAuth认证交互的,这里不会详细介绍OAuth,具体可以阅读OAuth官网列出的资源,另外即将上市的Flask新书里也提供了相关内容。
什么是第三方登录
简单来说,为一个网站添加第三方登录指的是提供通过其他第三方平台账号登入当前网站的功能。比如,使用QQ、微信、新浪微博账号登录。对于某些网站,甚至可以仅提供社交账号登录的选项,这样网站本身就不需要管理用户账户等相关信息。对用户来说,使用第三方登录可以省去注册的步骤,更加方便和快捷。
如果项目和GitHub、开源项目、编程语言等方面相关,或是面向的主要用户群是程序员时,可以仅支持GitHub的第三方登录,比如Gitter、GitBook、Coveralls和Travis CI等。在Flask程序中,除了手动实现,我们可以借助其他扩展或库,我们在这篇文章里要使用的GitHub-Flask扩展专门用于实现GitHub第三方登录,以及与GitHub进行Web API资源交互。
第三方登录授权流程
起这个标题是为了更好理解,具体来说,整个流程实际上是指OAuth2中Authorization Code模式的授权流程。为了便于理解,这里按照实际操作顺序列出了整个授权流程的实现步骤:
- 在GitHub为我们的程序注册OAuth程序,获得Client ID(客户端ID)和Client Secret(客户端密钥)。
- 我们在登录页面添加“使用GitHub登录”按钮,按钮的URL指向GitHub提供的授权URL,即https://github.com/login/oauth/authorize。
- 用户点击登录按钮,程序访问GitHub的授权URL,我们在授权URL后附加查询参数Client ID以及可选的Scope等。GitHub会根据授权URL中的Client ID识别出我们的程序信息,根据scope获取请求的权限范围,最后把这些信息显示在授权页面上。
- 用户输入GitHub的账户及密码,同意授权
- 用户同意授权后GitHub会将用户重定向到我们注册OAuth程序时提供的回调URL。如果用户同意授权,回调URL中会附加一个code(即Authorization Code,通常称为授权码),用来交换access令牌(即访问令牌,也被称为登录令牌、存取令牌等)。
- 我们在程序中接受到这个回调请求,获取code,发送一个POST请求到用于获取access令牌的URL,并附加Client ID、Client Secret和code值以及其他可选的值。
- GitHub接收到请求后,验证code值,成功后会再次向回调URL发起请求,同时在URL的查询字符串中或请求主体中加入access令牌的值、过期时间、token类型等信息。
- 我们的程序获取access令牌,可以用于后续发起API资源调用,或保存到数据库备用
- 如果用户是第一次登入,就创建用户对象并保存到数据库,最后登入用户
- 这里可选的步骤是让用户设置密码或资料
在GitHub注册OAuth程序
和其他主流第三方服务相同,GitHub使用OAuth2中的Authorization Code模式认证。因为认证后,根据授权的权限,客户端可以获取到用户的资源,为了便于对客户端进行识别和限制,我们需要在GitHub上进行注册,获取到客户端ID和密钥才能进行OAuth授权。
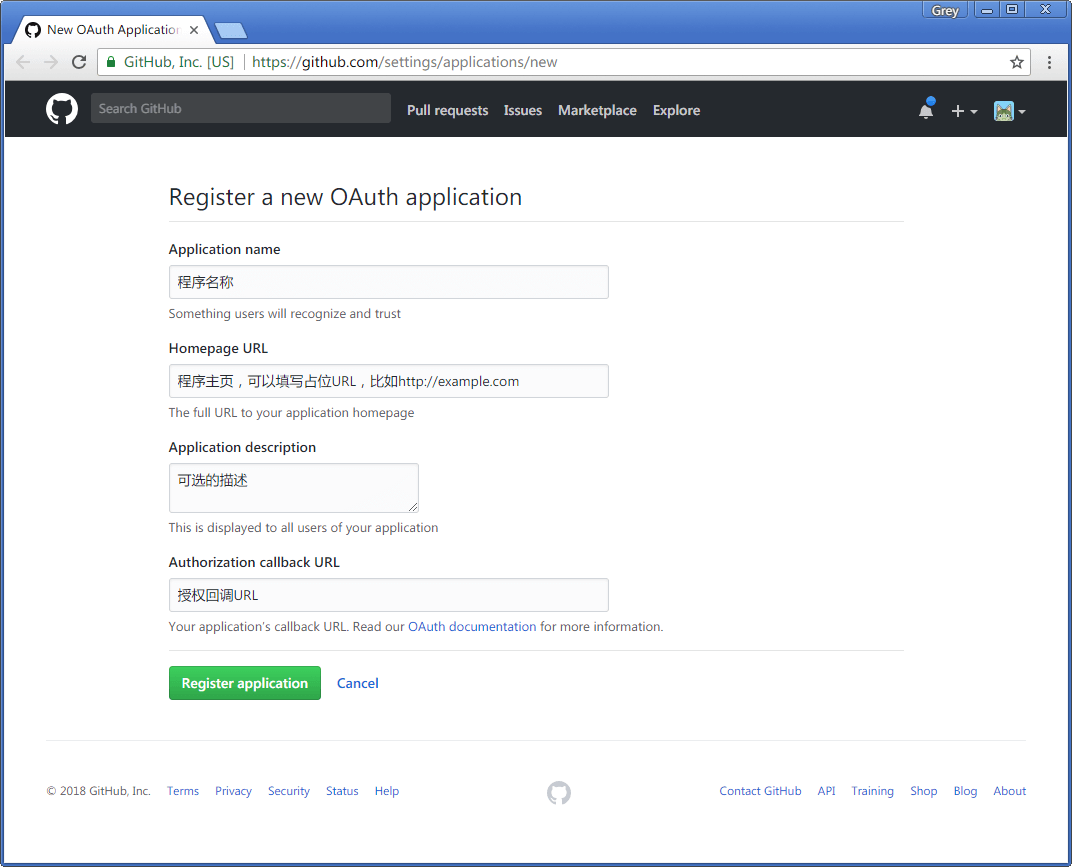
在服务提供方的网站上进行OAuth程序注册时,通常需要提供程序的基本信息,比如程序的名称、描述、主页等,这些信息会显示在要求用户授权的页面上,供用户识别。在GitHub中进行OAuth程序注册非常简单,访问https://github.com/settings/applications/new填写注册表单(如果你没有GitHub账户,那么需要先注册一个才能访问这个页面。),注册表单各个字段的作用和示例如图所示。

在GitHub注册OAuth程序
表单中的信息都可以后续进行修改。在开发时,程序的名称、主页和描述可以使用临时的占位内容。但Callback URL(回调URL)需要正确填写,这个回调URL用来在用户确认授权后重定向到程序中。因为我们需要在本地开发时进行测试,所以需要填写本地程序的URL,比如http://127.0.0.1:5000/callback/github,我们需要创建处理这个请求的视图函数,在这个视图函数中获取回调URL附加的信息,后面会详细介绍。
注意 这里因为是在开发时进行本地测试,所以填写了程序运行的地址,在生产环境要避免指定端口。另外,在这里localhost和127.0.0.1将会被视为两个地址。在程序部署上线时,你需要将这些地址更换为真实的网站域名地址。
注册成功后,我们会在重定向后的页面看到我们的Client ID(客户端ID)和Client Secret(客户端密钥),我们需要将这两个值分别赋值给配置变量GITHUB_CLIENT_ID和GITHUB_CLIENT_SECRET:
GITHUB_CLIENT_ID = 'GitHub客户端ID'
GITHUB_CLIENT_SECRET = 'GitHub客户端密钥'
注意 示例程序中为了便于测试,直接在脚本中写出了,在生产环境下,你应该将它们写入到环境变量,然后在脚本中从环境变量读取。
安装并初始化GitHub-Flask
首先使用pip或Pipenv等工具安装GitHub-Flask:
$ pip install github-flask
和其他扩展类似,你可以使用下面的方式初始化扩展(注意扩展类大小写):
from flask import Flask
from flask_github import GitHub
app = Flask(__name__)
github = GitHub(app)
如果你使用工厂函数创建程序,那么可以使用下面的方式初始化扩展:
from flask import Flask
from flask_github import GitHub
github = GitHub()
...
def create_app():
app = Flask(__name__)
app.config.from_pyfile('settings.py')
github.init_app(app)
...
return app
注意 虽然扩展名称是GitHub-Flask,但实际的包名称仍然是flask_github(Flask扩展名称可以倒置(即“Foo-Flask”),但包名称的形式必须为“flask_foo“。)。另外要注意扩展类的拼写,其中H为大写。
进行OAuth授权
创建用户模型
在示例程序中,我们首先进行了下面的基础工作:
- 定义基本配置
- 创建一个简单的用户模型来存储用户信息(使用Flask-SQLAlchemy)
- 实现登录和注销的管理功能(使用session实现,可以使用Flask-Login简化)
- 创建用于初始化数据库的命令函数
app = Flask(__name__)
app.config['SECRET_KEY'] = os.getenv('SECRET_KEY', 'secret string')
# Flask-SQLAlchemy
app.config['SQLALCHEMY_DATABASE_URI'] = os.getenv('DATABASE_URL', 'sqlite:///' + os.path.join(app.root_path, 'data.db'))
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
# 命令函数
@app.cli.command()
@click.option('--drop', is_flag=True, help='Create after drop.')
def initdb(drop):
"""Initialize the database."""
if drop:
db.drop_all()
db.create_all()
click.echo('Initialized database.')
# 存储用户信息的数据库模型类
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(100)) # 用户名
access_token = db.Column(db.String(200)) # 授权完成后获取的访问令牌
# 管理每个请求的登录状态,如果已登录(session里有用户id值),将模型类对象保存到g对象中
@app.before_request
def before_request():
g.user = None
if 'user_id' in session:
g.user = User.query.get(session['user_id'])
# 登入
@app.route('/login')
def login():
if session.get('user_id', None) is None:
... # 进行OAuth授权流程,具体见后面
flash('Already logged in.')
return redirect(url_for('index'))
# 登出
@app.route('/logout')
def logout():
session.pop('user_id', None)
flash('Goodbye.')
return redirect(url_for('index'))
现在我们可以执行上面创建的initdb命令来创建数据库和表(确保当前目录在demos/github-login下):
$ flask initdb
创建登录按钮
我们在本节一开始详细描述了以GitHub为例的完整的OAuth授权的过程,现在让我们来创建登录按钮。示例程序非常简单,只包含一个主页(index.html),这个页面由index视图处理:
@app.route('/')
def index():
is_login = True if g.user else False # 判断用户登录状态
return render_template('index.html', is_login=is_login)
这个视图在渲染模板时传入了用于判断用户登录状态的is_login变量,我们在模板中根据这个变量渲染不同的元素,如果已经登入,显示退出按钮,否则显示登入按钮:
{% if is_login %}
<a class="btn" href="{{ url_for('logout') }}">Logout</a>
{% else %}
<a class="btn" href="{{ url_for('login') }}">Login with GitHub</a>
{% endif %}
在实际的项目中,你可以使用GitHub的logo来让登录按钮更好看一些。
提示 使用Flask-Login时,你可以直接在模板中通过current_user.is_authenticated属性来判断用户登入状态。
发送授权请求
这个登录按钮的URL指向的是login视图,这个视图用来发送授权请求,如下所示:
@app.route('/login')
def login():
if session.get('user_id', None) is None: # 判断用户登录状态
return github.authorize(scope='repo')
flash('Already logged in.')
return redirect(url_for('index'))
在这个视图中,如果用户没有登录,我们就调用github.authorize()方法。这个方法会生成授权URL,并向这个URL发送请求。
附注 GitHub-Flask扩内置了除了客户端ID和密钥外所有必要的URL,比如API的URL,获取访问令牌的URL等(我们也可以通过相应的配置键进行修改,具体参考GitHub-Flask的文档)。
发起认证请求的URL中必须加入的参数是客户端ID,GitHub-Flask会自动使用我们之前通过配置变量传入的值。在授权URL中附加的可选参数如下所示:
|
名称
|
类型
|
说明
|
|
scope
|
字符串
|
请求的权限列表,使用空格分隔
|
|
state
|
字符串
|
用于CSRF保护的随机字符,也就是CSRF令牌
|
|
redirect_uri
|
字符串
|
用户授权结束后的重定向URL(必须是外部URL)
|
这三个参数都可以在调用github.authorize()方法时使用对应的名称作为关键字参数传入。
如果不设置scope,GitHub-Flask扩展默认设置为None,那么会拥有的权限是获取用户的公开信息。但是因为我们需要测试为项目加星(star)的操作,所以需要请求名为repo的权限值。
附注 选择scope时尽量只选择需要的内容,申请太多的权限可能会被用户拒绝。GitHub提供的所有的可用scope列表及其说明可以在GitHub开发文档看到。
如果不设置redirect_uri,那么GitHub会使用我们填写的callback URL。但是需要注意的是,如果我们填写了,那就必须和注册程序时填写的URL完全相同。我们在这里没有指定,因此将会使用注册OAuth程序时设置的http://localhost:5000/callback/github。
获取access令牌(访问令牌)
现在程序会重定向到GitHub的授权页面(会先要求登录GitHub),如下所示:
授权页面
当用户同意授权或拒绝授权后,GitHub会将用户重定向到我们设置的callback URL,我们需要创建一个视图函数来处理回调请求。如果用户同意授权,GitHub会在重定向的请求中加入code参数,一个临时生成的值,用于程序再次发起请求交换access token。程序这时需要向请求访问令牌URL(即https://github.com/login/oauth/access_token)发起一个POST请求,附带客户端ID、客户端密钥、code以及可选的redirect_uri和state。请求成功后的的响应会包含访问令牌(Access Token)。
很幸运,上面的一系列工作GitHub-Flask会在背后替我们完成。我们只需要创建一个视图函数,定义正确的URL规则(这里的URL规则需要和GitHub上填写的Callback URL匹配),并为其附加一个github.authorized_handler装饰器。另外,这个函数要接受一个access_token参数,GitHub-Flask会在授权请求结束后通过这个参数传入访问令牌,如下所示:
@app.route('/callback/github')
@github.authorized_handler
def authorized(access_token):
if access_token is None:
flash('Login failed.')
return redirect(url_for('index'))
# 下面会进行创建新用户,保存访问令牌,登入用户等操作,具体见后面
...
return redirect(url_for('chat.app'))
接受到GitHub返回的响应后,GitHub-Flask会调用这个authorized()函数,并传入access_token的值。如果授权失败,access_token的值会是None,这时我们重定向到主页页面,并显示一个错误消息。如果access_token不为None,我们会进行创建新用户,保存访问令牌,登入用户等操作,具体见下一节。
获取用户在GitHub上的资源
在获取到访问令牌后,我们需要做下面的工作:
- 判断用户是否已经存在于数据库中,如果存在就登入用户,更新访问令牌值(因为access是有过期时间的)
- 如果数据库中没有该用户,那么创建一个新的用户记录,传入对应的数据,最后登入用户
在这个示例程序中,我们使用用户名(username)作为用户的唯一标识,为了从数据库中查找对应的用户,我们需要获取用户在GitHub上的用户名。
如果授权成功,那么我们就使用这个访问令牌向GitHub提供的Web API的/user端点发起一次GET请求。这可以通过GitHub-Flask提供的get()方法实现,传入访问令牌作为access_token参数的值。我们把表示用户的资源端点“user”传入get()方法,因为GitHub-Flask会自动补全完整的请求URL,即https://api.github.com/user。
response = github.get('user', access_token=access_token)
提示 GitHub-Flask提供了一系列方法来调用GitHub通过Web API开放的资源。和在jQuery为AJAX提供的方法类似,它提供了底层的request()方法和方便的get()、post()、put()、delete()等方法(这些方法内部会调用request方法),可以用来发送不同HTTP方法的请求。
/user端点对应用户资料,返回的JSON数据如下所示:
{
"avatar_url": "https://avatars3.githubusercontent.com/u/12967000?v=4",
"bio": null,
"blog": "greyli.com",
"company": "None",
"created_at": "2015-06-19T13:00:23Z",
"email": "withlihui@gmail.com",
"events_url": "https://api.github.com/users/greyli/events{/privacy}",
"followers": 132,
"followers_url": "https://api.github.com/users/greyli/followers",
"following": 8,
"following_url": "https://api.github.com/users/greyli/following{/other_user}",
"gists_url": "https://api.github.com/users/greyli/gists{/gist_id}",
"gravatar_id": "",
"hireable": true,
"html_url": "https://github.com/greyli",
"id": 12967000,
"location": "China",
"login": "greyli",
"name": "Grey Li",
"node_id": "MDQ6VXNlcjEyOTY3MDAw",
"organizations_url": "https://api.github.com/users/greyli/orgs",
"public_gists": 7,
"public_repos": 61,
"received_events_url": "https://api.github.com/users/greyli/received_events",
"repos_url": "https://api.github.com/users/greyli/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/greyli/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/greyli/subscriptions",
"type": "User",
"updated_at": "2018-06-24T02:05:38Z",
"url": "https://api.github.com/users/greyli"
}
附注 用户端点返回的响应示例以及其他所有开放的资源端点可以在GitHub的API文档(https://developer.github.com/v3/)中看到。
GitHub-Flask会把GitHub的JSON响应主体解析为一个字典并返回,我们使用对应的键获取这些数据。其中登录用户名使用login作为键获取:
username = response['login']
获取到用户名后,我们判断是否已存在该用户,如果存在更新access_token字段值;如果不存在则创建一个新的User实例,把用户名和访问令牌存储到用户模型的对应字段里:
user = User.query.filter_by(username=username).first()
if user is None:
user = User(username=username, access_token=access_token)
db.session.add(user)
user.access_token = access_token # update access token
db.session.commit()
最后,我们登入对应的用户对象或是新创建的用户对象(将用户id写入session):
flash('Login success.')
# log the user in
# if you use flask-login, just call login_user() here.
session['user_id'] = user.id
因为我们需要在其他视图里调用GitHub资源,为了避免每次都获取和传入访问令牌,我们可以使用github.access_token_getter装饰器创建一个统一的令牌获取函数:
@github.access_token_getter
def token_getter():
user = g.user
if user is not None:
return user.access_token
当你在某处直接使用github.get()等方法而不传入访问令牌时,GitHub-Flask会通过你提供的这个回调函数来获取访问令牌。
注意 虽然在很多开源库的示例程序中,都会把access令牌存储到session中,但session不能用来存储敏感信息(具体可以访问专栏的这篇文章了解)。所以除了作测试用途,在生产环境下正确的做法是把访问令牌存储到数据库中。
现在,我们的主页视图需要更新,对于登录的用户,我们将会显示用户在GitHub上的资料:
@app.route('/')
def index():
if g.user:
is_login = True
response = github.get('user')
avatar = response['avatar_url']
username = response['name']
url = response['html_url']
return render_template('index.html', is_login=is_login, avatar=avatar, username=username, url=url)
is_login = False
return render_template('index.html', is_login=is_login)
类似的,我们使用github.get()方法获取/user端点的用户资料,因为设置了令牌获取函数,所以不用显式的传入访问令牌值。这些数据(头像、显示用户名和GitHub用户主页URL)将会显示在主页,如下图所示:
登录成功后的主页
因为我们在进行授权时请求了repo权限,我们还可以对用户的仓库进行各类操作,示例程序中添加了一个加星的示例,如果你登录后点击主页的“Star HelloFlask on GitHub”按钮,就会加星对应的仓库。这个按钮指向的star视图如下所示:
@app.route('/star/helloflask')
def star():
github.put('user/starred/greyli/helloflask', headers={'Content-Length': '0'})
flash('Star success.')
return redirect(url_for('index'))
完整的用于处理回调请求的authorized()视图函数如下所示:
@app.route('/callback/github')
@github.authorized_handler
def authorized(access_token):
if access_token is None:
flash('Login failed.')
return redirect(url_for('index'))
response = github.get('user', access_token=access_token)
username = response['login'] # get username
user = User.query.filter_by(username=username).first()
if user is None:
user = User(username=username, access_token=access_token)
db.session.add(user)
user.access_token = access_token # update access token
db.session.commit()
flash('Login success.')
# log the user in
# if you use flask-login, just call login_user() here.
session['user_id'] = user.id
return redirect(url_for('index'))
走进现实
一次完整的OAuth认证就这样完成了。在实际的项目中,支持第三方登录后,我们需要对原有的登录系统进行调整。通过第三方认证创建的用户没有密码,所以如果这部分用户使用传统方式登录的话会出现错误。我们添加一个if判断,如果用户对象的password_hash字段为空时,我们会返回一个错误提示,提醒用户使用上次使用的第三方服务进行登录,如下所示:
@app.route('/login', methods=['GET', 'POST'])
def login():
...
if request.method == 'POST':
...
user = User.query.filter_by(email=email).first()
if user is not None:
if user.password_hash is None:
flash('Please use the third patry service to log in.')
return redirect(url_for('.login'))
...
如果你想让用户也可以直接使用账户密码登录,那么可以在授权成功后重定向到新的页面请求用户设置密码。
相关链接