本文基于《Flask Web开发实战》第2章《Flask与HTTP》删减改写而来,完整的章节目录请访问本书主页http://helloflask.com/book查看。
本文中所指的示例程序在helloflask仓库的demos/http目录下。
HTTP(Hypertext Transfer Protocol,超文本传输协议)定义了服务器和客户端之间信息交流的格式和传递方式,它是万维网(World Wide Web)中数据交换的基础。在这篇文章中,我们会以HTTP协议定义的请求响应循环流程作为框架,了解Flask处理请求和响应的各种方式。
附注 HTTP的详细定义在RFC 7231~7235中可以看到。RFC(Request For Comment,请求评议)是一系列关于互联网标准和信息的文件,可以将其理解为互联网(Internet)的设计文档。完整的RFC列表可以在这里看到:https://tools.ietf.org/rfc/。
本章的示例程序在helloflask仓库的demos/http目录下,你可以通过下面的操作来运行程序:
$ git clone https://github.com/greyli/helloflask
$ cd helloflask
$ pipenv install
$ pipenv shell
$ cd demos/http
$ flask run
请求响应循环
为了更贴近现实,我们以一个真实的URL为例:
http://helloflask.com/hello
当我们在浏览器中的地址栏中输入这个URL,然后按下Enter,稍等片刻,浏览器会显示一个问候页面。这背后到底发生了什么?你一定可以猜想到,这背后也有一个类似我们第1章编写的程序运行着。它负责接收用户的请求,并把对应的内容返回给客户端,显示在用户的浏览器上。事实上,每一个Web应用都包含这种处理模式,即“请求-响应循环(Request-Response Cycle)”:客户端发出请求,服务器处理请求并返回响应,如下图所示:

请求响应循环示意图
附注 客户端(Client Side)是指用来提供给用户的与服务器通信的各种软件。在本书中,客户端通常指Web浏览器(后面简称浏览器),比如Chrome、Firefox、IE等;服务器端(Server Side)则指为用户提供服务的服务器,也是我们的程序运行的地方。
这是每一个Web程序的基本工作模式,如果再进一步,这个模式又包含着更多的工作单元,
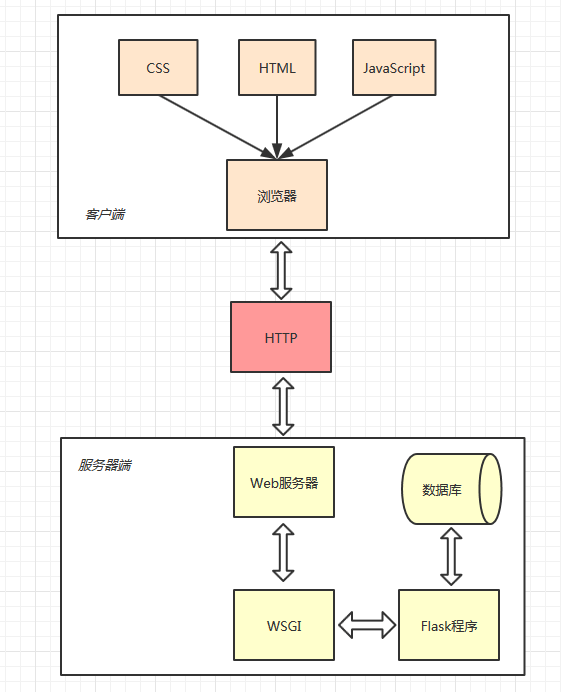
下图展示了一个Flask程序工作的实际流程:
Flask Web程序工作流程
从上图可以看出,HTTP在整个流程中起到了至关重要的作用,它是客户端和服务器端之间沟通的桥梁。
当用户访问一个URL,浏览器便生成对应的HTTP请求,经由互联网发送到对应的Web服务器。Web服务器接收请求,通过WSGI将HTTP格式的请求数据转换成我们的Flask程序能够使用的Python数据。在程序中,Flask根据请求的URL执行对应的视图函数,获取返回值生成响应。响应依次经过WSGI转换生成HTTP响应,再经由Web服务器传递,最终被发出请求的客户端接收。浏览器渲染响应中包含的HTML和CSS代码,并执行JavaScript代码,最终把解析后的页面呈现在用户浏览器的窗口中。
提示 关于WSGI的更多细节,我们会在第16章进行详细介绍。
提示 这里的服务器指的是处理请求和响应的Web服务器,比如我们上一章介绍的开发服务器,而不是指物理层面上的服务器主机。
HTTP请求
URL是一个请求的起源。不论服务器是运行在美国洛杉矶,还是运行在我们自己的电脑上,当我们输入指向服务器所在地址的URL,都会向服务器发送一个HTTP请求。一个标准的URL由很多部分组成,以下面这个URL为例:
http://helloflask.com/hello?name=Grey
这个URL的各个组成部分如下表所示:
|
信息
|
说明
|
|
http://
|
协议字符串,指定要使用的协议
|
|
helloflask.com
|
服务器的地址(域名)
|
|
/hello?name=Grey
|
要获取的资源路径(path),类似Unix的文件目录结构
|
附注 这个URL后面的?name=Grey部分是查询字符串(query string)。URL中的查询字符串用来向指定的资源传递参数。查询字符串从问号?开始,以键值对的形式写出,多个键值对之间使用&分隔。
请求报文
当我们在浏览器中访问这个URL时,随之产生的是一个发向http://helloflask.com所在服务器的请求。请求的实质是发送到服务器上的一些数据,这种浏览器与服务器之间交互的数据被称为报文(message),请求时浏览器发送的数据被称为请求报文(request message),而服务器返回的数据被称为响应报文(response message)。
请求报文由请求的方法、URL、协议版本、首部字段(header)以及内容实体组成。前面的请求产生的请求报文示意如下表所示:
|
组成说明
|
请求报文内容
|
|
报文首部:请求行(方法、URL、协议)
|
GET /hello HTTP/1.1
|
|
报文首部:各种首部字段
|
Host: helloflask.com
Connection: keep-alive
Cache-Control: max-age=0
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36
…
|
|
空行
|
|
|
报文主体
|
name=Grey
|
如果你想看看真实的HTTP报文,可以在浏览器中向任意一个有效的URL发起请求,然后在浏览器的开发者工具(F12)里的Network标签中看到URL对应资源加载的所有请求列表,点击任一个请求条目即可看到报文信息,下图是使用Chrome访问本地的示例程序的示例:
在Chrome浏览器中查看请求和响应报文
报文由报文首部和报文主体组成,两者由空行分隔,请求报文的主体一般为空。如果URL中包含查询字符串,或是提交了表单,那么报文主体将会是查询字符串和表单数据。
HTTP通过方法来区分不同的请求类型。比如,当你直接访问一个页面时,请求的方法是GET;当你在某个页面填写了表单并提交时,请求方法则通常为POST。下表是常见的几种HTTP方法类型:
|
方法
|
说明
|
|
GET
|
获取资源
|
|
POST
|
传输数据
|
|
PUT
|
传输文件
|
|
DELETE
|
删除资源
|
|
HEAD
|
获得报文首部
|
|
OPTIONS
|
询问支持的方法
|
报文首部包含了请求的各种信息和设置,比如客户端的类型,是否设置缓存,语言偏好等等。
附注 HTTP中可用的首部字段列表可以在https://www.iana.org/assignments/message-headers/message-headers.xhtml看到。请求方法的详细列表和说明可以在RFC 7231中看到。
如果运行了示例程序,那么当你在浏览器中访问http://127.0.0.1:5000/hello,开发服务器会在命令行中输出一条记录日志,其中包含请求的主要信息:
127.0.0.1 - - [02/Aug/2017 09:51:37] "GET /hello HTTP/1.1" 200 –
Request对象
现在该让Flask的请求对象request出场了,这个请求对象封装了从客户端发来的请求报文,我们能从它获取请求报文中的所有数据。
注意 请求解析和响应封装实际上大部分是由Werkzeug完成的,Flask子类化Werkzeug的请求(Request)和响应(Response)对象并添加了和程序相关的特定功能。在这里为了方便理解,我们先略过不谈。在第16章,我们会详细了解Flask的工作原理。
和上一节一样,我们先从URL说起。假设请求的URL是http://helloflask.com/hello?name=Grey,当Flask接收到请求后,请求对象会提供多个属性来获取URL的各个部分,常用的属性如下表所示:
|
属性
|
值
|
|
path
|
u’/hello’
|
|
full_path
|
u’/hello?name=Grey’
|
|
host
|
u’helloflask.com’
|
|
host_url
|
u’http://helloflask.com/ ‘
|
|
base_url
|
u’http://helloflask.com/hello ‘
|
|
url
|
u’http://helloflask.com/hello?name=Grey ‘
|
|
url_root
|
u’http://helloflask.com/ ‘
|
除了URL,请求报文中的其他信息都可以通过request对象提供的属性和方法获取,其中常用的部分如下表所示:
|
属性/方法
|
说明
|
|
args
|
Werkzeug的ImmutableMultiDict对象。存储解析后的查询字符串,可通过字典方式获取键值。如果你想获取未解析的原生查询字符串,可以使用query_string属性
|
|
blueprint
|
当前蓝本的名称,关于蓝本的概念在本书第二部分会详细介绍
|
|
cookies
|
一个包含所有随请求提交的cookies的字典
|
|
data
|
包含字符串形式的请求数据
|
|
endpoint
|
与当前请求相匹配的端点值
|
|
files
|
Werkzeug的MultiDict对象,包含所有上传文件,可以使用字典的形式获取文件。使用的键为文件input标签中的name属性值,对应的值为Werkzeug的FileStorage对象,可以调用save()方法并传入保存路径来保存文件
|
|
form
|
Werkzeug的ImmutableMultiDict对象。类似files,包含解析后的表单数据。表单字段值通过input标签的name属性值作为键获取
|
|
values
|
Werkzeug的CombinedMultiDict对象,结合了args和form属性的值
|
|
get_data(cache=True, as_text=False, parse_from_data=False)
|
获取请求中的数据,默认读取为字节字符串(bytestring),将as_text设为True返回值将是解码后的unicode字符串
|
|
get_json(self, force=False, silent=False, cache=True)
|
作为JSON解析并返回数据,如果MIME类型不是JSON,返回None(除非force设为True);解析出错则抛出Werkzeug提供的BadRequest异常(如果未开启调试模式,则返回400错误响应,后面会详细介绍),如果silent设为True则返回None;cache设置是否缓存解析后的JSON数据
|
|
headers
|
一个Werkzeug的EnvironHeaders对象,包含首部字段,可以以字典的形式操作
|
|
is_json
|
通过MIME类型判断是否为JSON数据,返回布尔值
|
|
json
|
包含解析后的JSON数据,内部调用get_json(),可通过字典的方式获取键值
|
|
method
|
请求的HTTP方法
|
|
referrer
|
请求发起的源URL,即referer
|
|
scheme
|
请求的URL模式(http或https)
|
|
user_agent
|
用户代理(User Agent,UA),包含了用户的客户端类型,操作系统类型等信息
|
提示 Werkzeug的MutliDict类是字典的子类,它主要实现了同一个键对应多个值的情况。比如一个文件上传字段可能会接收多个文件。这时就可以通过getlist()方法来获取文件对象列表。而ImmutableMultiDict类继承了MutliDict类,但其值不可更改。具体访问Werkzeug文档相关数据结构章节http://werkzeug.pocoo.org/docs/latest/datastructures/。
在我们的示例程序中实现了同样的功能。当你访问http://localhost:5000/hello?name=Grey,页面加载后会显示“Hello, Grey!”。这说明处理这个URL的视图函数从查询字符串中获取了查询参数name的值,如下所示:
from flask import Flask, request
app = Flask(__name__)
@app.route('/hello')
def hello():
name = request.args.get('name', 'Flask') # 获取查询参数name的值
return '<h1>Hello, %s!</h1>' % name # 插入到返回值中
注意 上面的示例代码包含安全漏洞,在现实中我们要避免直接将用户传入的数据直接作为响应返回,在本章的末尾我们将介绍包括这个漏洞在内的Web常见安全漏洞的具体细节和防范措施。
需要注意的是,和普通的字典类型不同,当我们从request对象中类型为MutliDict或ImmutableMultiDict的属性(比如files、form、args)中直接使用键作为索引获取数据时(比如request.args[‘name’]),如果没有对应的键,那么会返回HTTP 400错误响应(Bad Request,表示请求无效),而不是抛出KeyError异常,如下图所示。为了避免这个错误,我们应该使用get()方法获取数据,如果没有对应的值则返回None;get()方法的第二个参数可以设置默认值,比如requset.args.get(‘name’, ‘Human’)。
400错误响应
提示 如果开启了调试模式,那么会抛出BadRequestKeyError异常并显示对应的错误堆栈信息,而不是常规的400响应。
在Flask中处理请求
URL是指向网络上资源的地址。在Flask中,我们需要让请求的URL匹配对应的视图函数,视图函数返回值就是URL对应的资源。
路由匹配
为了便于将请求分发到对应的视图函数,程序实例中存储了一个路由表(app.url_map),其中定义了URL规则和视图函数的映射关系。当请求发来后,Flask会根据请求报文中的URL(path部分)来尝试与这个表中的所有的URL规则进行匹配,调用匹配成功的视图函数。如果没有找到匹配的URL规则,说明程序中没有处理这个URL的视图函数,Flask会自动返回404错误响应(Not Found,表示资源未找到)。你可以尝试在浏览器中访问http://localhost:5000/nothing,因为我们的程序中没有视图函数负责处理这个URL,所以你会得到404响应,如下图所示:
404错误响应
如果你经常上网,那么肯定会对这个错误代码相当熟悉,它表示请求的资源没有找到。和前面提及的400错误响应一样,这类错误代码被称为HTTP状态码,用来表示响应的状态,具体会在下面详细讨论。
当请求的URL与某个视图函数的URL规则匹配成功时,对应的视图函数就会被调用。使用flask routes命令可以查看程序中定义的所有路由,这个列表由app.url_map解析得到:
$ flask routes
Endpoint Methods Rule
-------- ------- -----------------------
hello GET /hello
go_back GET /goback/<int:age>
hi GET /hi
...
static GET /static/<path:filename>
在输出的文本中,我们可以看到每个路由对应的端点(Endpoint)、HTTP方法(Methods)和URL规则(Rule),其中static端点是Flask添加的特殊路由,用来访问静态文件,具体我们会在第3章学习。
设置监听的HTTP方法
在上一节通过flask routes命令打印出的路由列表可以看到,每一个路由除了包含URL规则外,还设置了监听的HTTP方法。GET是最常用的HTTP方法,所以视图函数的默认监听的方法类型就是GET,HEAD、OPTIONS方法的请求由Flask处理,而像DELETE、PUT等方法一般不会在程序中实现,在后面我们构建Web API时才会用到这些方法。
我们可以在app.route()装饰器中使用methods参数传入一个包含监听的HTTP方法的可迭代对象。比如,下面的视图函数同时监听GET请求和POST请求:
@app.route('/hello', methods=['GET', 'POST'])
def hello():
return '<h1>Hello, Flask!</h1>'
当某个请求的方法不符合要求时,请求将无法被正常处理。比如,在提交表单时通常使用POST方法,而如果提交的目标URL对应的视图函数只允许GET方法,这时Flask会自动返回一个405错误响应(Method Not Allowed,表示请求方法不允许),如下图所示:
405错误响应
通过定义方法列表,我们可以为同一个URL规则定义多个视图函数,分别处理不同HTTP方法的请求,我们在本书第二部分构建Web API时会用到这个特性。
3. URL处理
从前面的路由列表中可以看到,除了/hello,这个程序还包含许多URL规则,比如和go_back端点对应的/goback/<int:year>。现在请尝试访问http://localhost:5000/goback/34,在URL中加入一个数字作为时光倒流的年数,你会发现加载后的页面中有通过传入的年数计算出的年份:“Welcome to 1984!”。仔细观察一下,你会发现URL规则中的变量部分有一些特别,<int:year>表示为year变量添加了一个int转换器,Flask在解析这个URL变量时会将其转换为整型。URL中的变量部分默认类型为字符串,但Flask提供了一些转换器可以在URL规则里使用,如下表所示:
|
转换器
|
说明
|
|
string
|
不包含斜线的字符串(默认值)
|
|
int
|
整型
|
|
float
|
浮点数
|
|
path
|
包含斜线的字符串。static路由的URL规则中的filename变量就使用了这个转换器
|
|
any
|
匹配一系列给定值中的一个元素
|
|
uuid
|
UUID字符串
|
转换器通过特定的规则指定,即“<转换器:变量名>”。<int:year>把year的值转换为整数,因此我们可以在视图函数中直接对year变量进行数学计算:
@app.route('goback/<int:year>')
def go_back(year):
return '<p>Welcome to %d!</p>' % (2018 - year)
默认的行为不仅仅是转换变量类型,还包括URL匹配。在这个例子中,如果不使用转换器,默认year变量会被转换成字符串,为了能够在Python中计算天数,我们就需要使用int()函数将year变量转换成整型。但是如果用户输入的是英文字母,就会出现转换错误,抛出ValueError异常,我们还需要手动验证;使用了转换器后,如果URL中传入的变量不是数字,那么会直接返回404错误响应。比如,你可以尝试访问http://localhost:5000/goback/tang。
在用法上唯一特别的是any转换器,你需要在转换器后添加括号来给出可选值,即“<any(value1, value2, …):变量名>”,比如:
@app.route('/colors/<any(blue, white, red):color>')
def three_colors(color):
return '<p>Love is patient and kind. Love is not jealous or boastful or proud or rude.</p>'
当你在浏览器中访问http://localhost:5000/colors/<color>时,如果将<color>部分替换为any转换器中设置的可选值以外的任意字符,均会获得404错误响应。
如果你想在any转换器中传入一个预先定义的列表,可以通过格式化字符串的方式(使用%或是format()函数)来构建URL规则字符串,比如:
colors = ['blue', 'white', 'red']
@app.route('/colors/<any(%s):color>' % str(colors)[1:-1])
...
HTTP响应
在Flask程序中,客户端发出的请求触发相应的视图函数,获取返回值会作为响应的主体,最后生成完整的响应,即响应报文。
响应报文
响应报文主要由协议版本、状态码(status code)、原因短语(reason phrase)、响应首部和响应主体组成。以发向localhost:5000/hello的请求为例,服务器生成的响应报文示意如下表所示:
|
组成说明
|
响应报文内容
|
|
报文首部:状态行(协议、状态码、原因短语)
|
HTTP/1.1 200 OK
|
|
报文首部:各种首部字段
|
Content-Type: text/html; charset=utf-8
Content-Length: 22
Server: Werkzeug/0.12.2 Python/2.7.13
Date: Thu, 03 Aug 2017 05:05:54 GMT
…
|
|
空行
|
|
|
报文主体
|
<h1>Hello, Human!</h1>
|
响应报文的首部包含了一些关于响应和服务器的信息,这些内容由Flask生成,而我们在视图函数中返回的内容即为响应报文中的主体内容。浏览器接受到响应后,会把返回的响应主体解析并显示在浏览器窗口上。
HTTP状态码用来表示请求处理的结果,下表是常见的几种状态码和相应的原因短语:
|
类型
|
状态码
|
原因短语(用于解释状态码)
|
说明
|
|
成功
|
200
|
OK
|
请求被正常处理
|
|
201
|
Created
|
请求被处理,并创建了一个新资源
|
|
204
|
No Content
|
请求处理成功,但无内容返回
|
|
重定向
|
301
|
Moved Permanently
|
永久重定向
|
|
302
|
Found
|
临时性重定向
|
|
304
|
Not Modified
|
请求的资源未被修改,重定向到缓存的资源
|
|
客户端错误
|
400
|
Bad Request
|
表示请求无效,即请求报文中存在错误
|
|
401
|
Unauthorized
|
类似403,表示请求的资源需要获取授权信息,在浏览器中会弹出认证弹窗
|
|
403
|
Forbidden
|
表示请求的资源被服务器拒绝访问
|
|
404
|
Not Found
|
表示服务器上无法找到请求的资源或URL无效
|
|
服务器端错误
|
500
|
Internal Server Error
|
服务器内部发生错误
|
提示 当关闭调试模式时,即FLASK_ENV使用默认值production,如果程序出错,Flask会自动返回500错误响应;而调试模式下则会显示调试信息和错误堆栈。
附注 响应状态码的详细列表和说明可以在RFC 7231中看到。
在Flask中生成响应
响应在Flask中使用Response对象表示,响应报文中的大部分内容由服务器处理,大多数情况下,我们只负责返回主体内容。
根据我们在请求一节介绍的内容,Flask会先判断是否可以找到与请求URL相匹配的路由,如果没有则返回404响应。如果找到,则调用对应的视图函数,视图函数的返回值构成了响应报文的主体内容,正确返回时状态码默认为200。Flask会调用make_response()方法将视图函数返回值转换为响应对象。
完整的说,视图函数可以返回最多由三个元素组成的元组:响应主体、状态码、首部字段。其中首部字段可以为字典,或是两元素元组组成的列表。
比如,普通的响应可以只包含主体内容:
@app.route('/hello')
def hello():
...
return '<h1>Hello, Flask!</h1>'
默认的状态码为200,下面指定了不同的状态码:
@app.route('/hello')
def hello():
...
return '<h1>Hello, Flask!</h1>', 201
有时你会想附加或修改某个首部字段。比如,要生成状态码为3XX的重定向响应,需要将首部中的Location字段设置为重定向的目标URL:
@app.route('/hello')
def hello():
...
return '', 302, {'Location': 'http://www.example.com'}
现在访问http://localhost:5000/hello,会重定向到http://www.example.com。在多数情况下,除了响应主体,其他部分我们通常只需要使用默认值即可。
重定向
如果你访问http://localhost:5000/hi,你会发现页面加载后地址栏中的URL变为了http://localhost:5000/hello。这种行为被称为重定向(Redirect),你可以理解为网页跳转。在上一节的示例中,状态码为302的重定向响应的主体为空,首部中需要将Location字段设为重定向的目标URL,浏览器接受到重定向响应后会向Location字段中的目标URL发起新的GET请求,整个流程下图所示:
重定向流程示意图
在Web程序中,我们经常需要进行重定向。比如,当某个用户在没有经过认证的情况下访问需要登录后才能访问的资源,程序通常会重定向到登录页面。
对于重定向这一类特殊响应,Flask提供了一些辅助函数。除了像前面那样手动生成302响应,我们可以使用Flask提供的redirect()函数来生成重定向响应,重定向的目标URL作为第一个参数。前面的例子可以简化为:
from flask import Flask, redirect
...
@app.route('/hello')
def hello():
return redirect('http://www.example.com')
提示 使用redirect()函数时,默认的状态码为302,即临时重定向。如果你想修改状态码,可以在redirect()函数中作为第二个参数或使用code关键字传入。
如果要在程序内重定向到其他视图,那么只需在redirect()函数中使用url_for()函数生成目标URL即可,如下所示:
from flask import Flask, redirect, url_for
...
@app.route('/hi')
def hi():
...
return redierct(url_for('hello')) # 重定向到/hello
@app.route('/hello')
def hello():
...
错误响应
如果你访问http://localhost:5000/brew/coffee,你会获得一个418错误响应(I’m a teapot),如下图所示:
418错误响应
附注 418错误响应由IETF(Internet Engineering Task Force,互联网工程任务组)在1998年愚人节发布的HTCPCP(Hyper Text Coffee Pot Control Protocol,超文本咖啡壶控制协议)中定义(玩笑),当一个控制茶壶的 HTCPCP 收到 BREW 或 POST 指令要求其煮咖啡时应当回传此错误。
大多数情况下,Flask会自动处理常见的错误响应。HTTP错误对应的异常类在Werkzeug的werkzeug.exceptions模块中定义,抛出这些异常即可返回对应的错误响应。如果你想手动返回错误响应,更方便的方法是使用Flask提供的abort()函数。
在abort()函数中传入状态码即可返回对应的错误响应,下面的视图函数返回404错误响应:
from flask import Flask, abort
...
@app.route('/404')
def not_found():
abort(404)
提示 abort()函数前不需要使用return语句,但一旦abort()函数被调用,abort()函数之后的代码将不会被执行。
附注 虽然我们有必要返回正确的状态码,但这并不是必须的。比如,当某个用户没有权限访问某个资源时,返回404错误要比403错误更加友好。
本文基于《Flask Web开发实战》第2章《Flask与HTTP》删减改写而来,完整的章节目录请访问本书主页http://helloflask.com/book查看。